
MAE-DFER-CA
MAE-DFER-CA extends the masked autoencoder framework for dynamic facial expression recognition (DFER) by integrating a Channel Attention (CA) module to enhance subtle muscle motion pattern learning. This work builds upon the MAE-DFER architecture, which employs the LGI-Former encoder for efficient self-supervised video representation.
Key Features:
Self-supervised masked autoencoder based on MAE-DFER, reducing annotation dependence for dynamic facial emotion recognition.
Integrates channel attention (CA_Module, inspired by MMNET) to enhance subtle motion pattern learning between video frames.
Achieves stable accuracy gains (WAR 52.40 on FERV39k) with only a minimal increase in computational cost (FLOPs).
Validated consistent improvement over the original MAE-DFER on real-world benchmark datasets.
System Overview
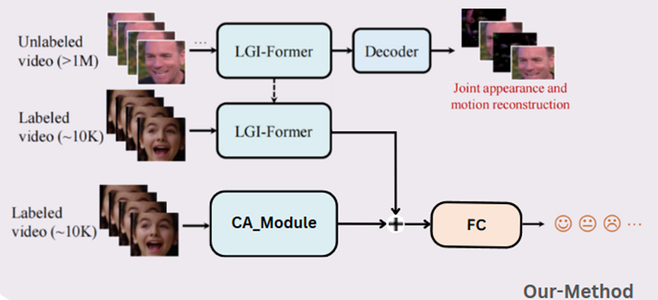
Overview of the MAE-DFER framework with integrated Channel Attention module.
The framework models both spatial and temporal features by combining joint masked appearance and motion reconstruction with channel attention, enabling improved recognition of subtle, dynamic facial expressions in video sequences.
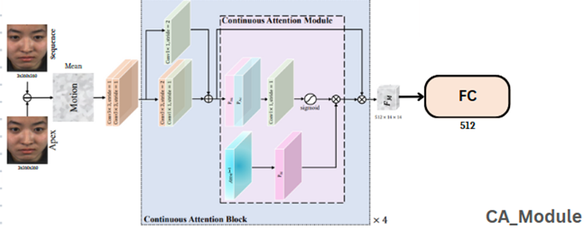
Architecture of the Channel Attention (CA) module, adapted from micro-expression recognition techniques.
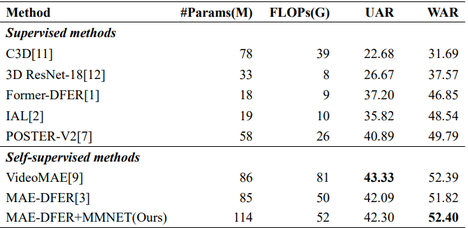
Performance comparison on the FERV39k dataset, highlighting the consistent gain from the Channel Attention integration.